Leveraging Apache Spark to build scalable, high-performance data solutions that enable real-time processing, advanced analytics, and intelligent decision-making for modern businesses.
Leveraging Apache Spark to deliver real-time data streaming and event processing that ensures timely insights and smarter business decisions.
Harnessing Spark’s distributed computing power to analyze massive datasets efficiently, uncovering trends and opportunities for business growth.
Building scalable ML pipelines with Spark MLlib to accelerate predictive analytics, intelligent automation, and data-driven decision-making.
Designing robust Extract, Transform, and Load (ETL) processes with Spark to simplify data integration and ensure clean, reliable, and usable data.
Integrating Spark seamlessly with cloud platforms and enterprise systems to create scalable, future-ready big data ecosystems.
Powering real-time IoT and streaming applications with Spark Structured Streaming, enabling instant insights and faster response times.
Let’s work together to turn your idea into a powerful and successful tech product.
CONTACT US ➔
Empowering enterprises with high-performance distributed data processing, analytics, and AI integration.
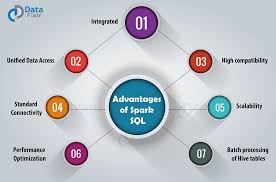
Leverage Spark SQL for fast, distributed querying across massive datasets. With support for structured and semi-structured data, Spark SQL enables interactive analysis, ad-hoc queries, and seamless integration with BI tools.

Unlock advanced network and relationship analytics with Spark’s GraphX and GraphFrames. From social network analysis to supply chain optimization, Spark enables large-scale graph computation and visualization.

Accelerate AI and deep learning workflows by integrating Spark with MLlib, TensorFlow, and PyTorch. Spark’s distributed architecture allows scalable model training, hyperparameter tuning, and inference across vast datasets.

Optimize and scale generative AI and LLM workloads with Spark. From data preprocessing and fine-tuning to large-scale inference, Spark provides the compute power needed for AI applications like chatbots and intelligent automation.
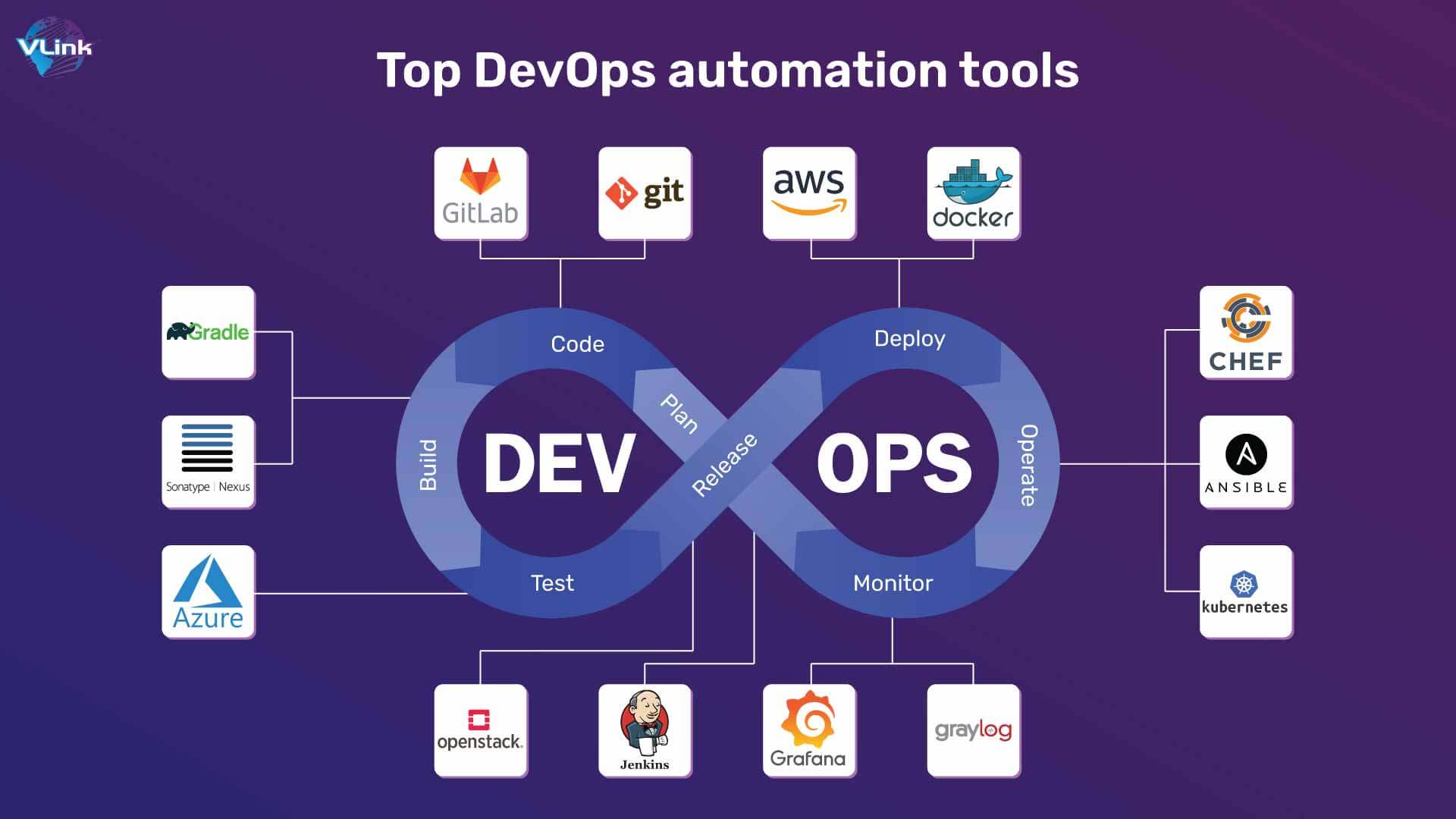
Enable reliable and automated Spark operations with DevOps practices. Implement CI/CD pipelines, containerized deployments, IaC, and automated scaling strategies for Spark environments to ensure consistent performance.

Harness Spark’s in-memory processing for financial analytics — from fraud detection and risk modeling to portfolio monitoring and high-frequency trading. Spark delivers speed, scalability, and reliability for mission-critical workloads.
Curious about leveraging Apache Spark for big data analytics and real-time processing? At Synaipsys, we’ve compiled answers to common queries about Spark and its enterprise use cases.
Apache Spark provides high-speed data processing with in-memory computation and supports diverse workloads.
Spark is versatile and can be used for:
Spark offers APIs for multiple languages, making it developer-friendly:
Spark uses resilient distributed datasets (RDDs) for reliable fault tolerance:
Yes, Spark integrates seamlessly with multiple tools and ecosystems: